A Beginner's Guide to Local Large Language Models (LLMs)
Introduction
If you're intrigued by large language models (LLMs) but feel overwhelmed by the torrent of new information flooding the internet, you're not alone. New models, white papers, and products come out every day as the field is rapidly evolving. This guide aims to clarify LLMs like ChatGPT, Phind, and others, enough that a first-year computer science student can understand the basics of how this technology works and have some key insights into how they can best take advantage of it.
Basics Ideas
The life cycle of LLMs consists of 3 primary phases:
- The design or architecture
- Training the model
- Deploying the model or making inferences.
Architecture
Designing an LLM requires a Master's Degree in computer science, years of research and experience, and extensive resources. A detailed explanation of this topic is way outside the scope of this article, so I won't attempt to explain it and instead give my recommendations on where to start. In general, LLMs are sophisticated algorithmic constructs such as Transformers, RNNs (Recurrent Neural Networks), CNNs (Convolutional Neural Networks), and their hybrids, designed for processing and generating natural language. To understand this topic beyond the high-level jargon, I recommend obtaining hands-on experience with first principles and libraries such as PyTorch and TensorFlow. I started by following tutorials on how to build a simple CNN with TensorFlow and train it to detect handwritten numbers. It is my opinion that a student needs lots of hands-on experience programming basic models before it is worth diving into the more complex areas of machine learning like modern LLMs a topic which I have admittedly not gotten far in.
Training
During this phase, LLMS are trained by adjusting weights or biases (numbers) stored in giga-byte amounts of RAM and processed/optimized with thousands (sometimes millions) of parallel cores. The training algorithms are quite complex with extensive research into optimal methodology and algorithms. One core idea, that many of us are aware of, is optimization in infinitesimal calculus. That is the process of finding the maximum and minimum in a given function.
This tells us that the maximums and miniums of are at .
Similarly, yet a little more complex, is an optimization functions such as Gradient Descent. Gradient descent is computational method for a multidimensional optimization, i.e. finding the lowest value in a multidemensional Function such as (but could generalize to a function of many more varibles ). Additionally, this algorithm has a mitigation strategies for detecting local minimums which adds additional complexity to it's design.
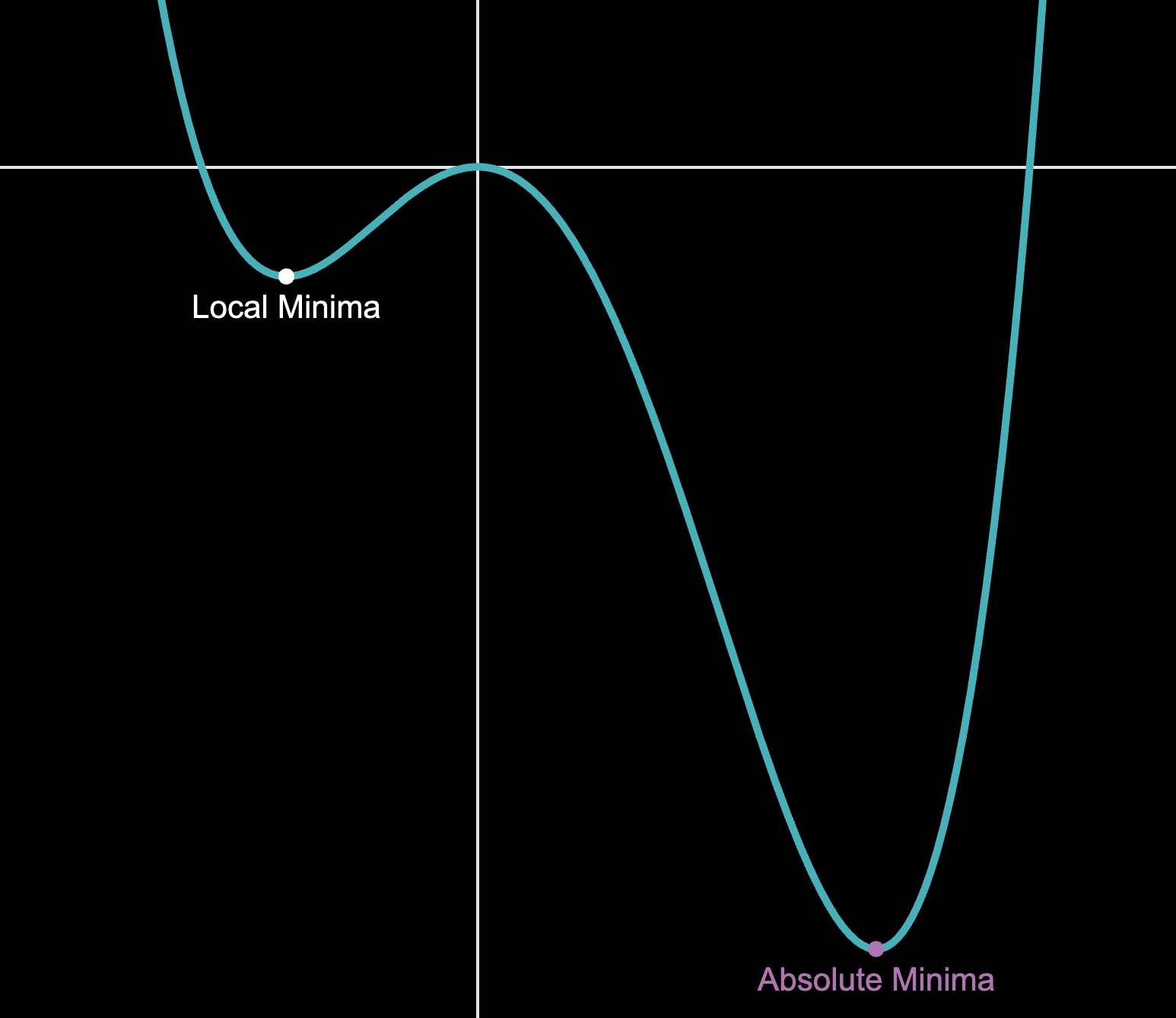 Consider how you might know there isn't an even lower Minima, out side the domain of this graph, if you weren't allowed to use calculus (i.e. you don't know the derivative and can't easily calculate it), but instead used an alternative method. How would you be sure you knew there wasn't an other minima?
Consider how you might know there isn't an even lower Minima, out side the domain of this graph, if you weren't allowed to use calculus (i.e. you don't know the derivative and can't easily calculate it), but instead used an alternative method. How would you be sure you knew there wasn't an other minima?
The reason this idea is core to training an LLM is that gradient descent (or similar methods) is the bulk of processing power (time complexity) for training a model as it determines how to adjust the biases. Moreover, what it all boils down to is floating-point calculations performed during gradient descent. A process that graphics cards and historically gaming consoles like PS3s have accelerated.
 Photo Credit: U.S. Department of Defense
Photo Credit: U.S. Department of Defense
Deployment
Once trained, these models are deployed to make inferences based on inputs. Inferences are the aspect that end users are most aware of. For example, inferences may be communicating with a chatbot or deriving sentiment from a headline. Unlike training, when using the model to make an inference, there's no computationally intensive aspect. Instead, it makes use of the precalculated weights and a light algorithm, such as the nearest k method, to infer context. In other words, you provide context, and the algorithm predicts the next outputted word or token by finding the best path through weighted values.
- Architecture: The structural design and choice of algorithms.
- Training: Learning from data, adjusting weights, and biases.
- Inferences: The application phase where the trained model makes predictions (performs tasks like text generation or sentiment analysis).
The Role of Consumer Hardware in LLMs
The focus here is local deployment, meaning you can use these models directly on your machine without an internet connection. Local models offer several advantages, such as increased reliability (no cloud outages), enhanced privacy, and the freedom to customize your experience without limitations. Local models put control back in the user's hands, allowing you to tailor LLMs to your needs.
Ensuring you have the proper hardware is the first step in your journey with Local Large Language Models (LLMs). The primary challenge in LLM inferencing is the need for significant amounts of high-speed memory and at least a few parallel processing cores (though parallel cores matter much less for inferencing than training).
Key Consumer Hardware Options for LLMs:
| Hardware Option | Pros | Cons |
|---|---|---|
| Nvidia Consumer GPUs | - Modern architecture (Ada Lovelace, Ampere) is faster than older generations - Easy to configure with Nvidia frameworks - HDMI outputs available for graphical applications | - Not specifically optimized for LLM tasks |
| Nvidia Workstation GPUs | - Large memory size and bandwidth ideal for inferencing and training - Cost-effective older models on secondary markets | - High airflow requirements due to heat generation - Older models may lack long-term support |
| Apple's M Architecture | - Up to 192GB RAM - Can operate headlessly or within Apple ecosystem - Includes user-friendly LLM Studio software | - High cost - 24-core GPU is better suited for inferencing, not training |
| Cloud-Based Alternatives | - Scalable and adaptable to workload needs - Provides access to the latest high-performance hardware | - May not suit users who need a local LLM setup |
Note: For inferencing, memory size and bandwidth are often more critical than raw compute power.
Unfortunately, I can not recommend alternatives like AMD and Intel GPUs because they lack support for CUDA and, therefore, will not be as user-friendly. I mention this because it is essential that we consumers use both AMD and Intel when support is added to avoid one company having all the power and limited future options. Additionally, A powerful CPU coupled with ample, high-speed RAM still is not a viable setup for inferencing as the memory bandwith on DDR6 is still to slow. Unfortunately, most applications need vram for reasonable performance.
Model Selection
Selecting a model can be very overwhelming as new models come out every hour on HuggingFace. I hope to provide some brief information to help give some background on parameters, quantization, loaders, and design theories that will help guide you when choosing the best model for your needs.
One of the first things you will encounter when selecting a model is parameters. The rule is that the more parameters there are, the better the ability to capture patterns in data and produce output with an illusion of reasoning. However, you must choose a model that will fit in your vram otherwise splitting the data will cause your model to perform at crawling speeds. Another concept to be aware of is overfitting. However, overfitting is less of an end-user concern and more of a design consideration, it is worth noting that more parameters increase the risk of overfitting and generalizing too much decreasing the model's overall performance.
Below is an interactive calculator showing roughly how large of a model you can use with your hardware based on how much video memory you have.
LLM paramter calculation
Result: 0.27 billion parameters
Or (if by paramters) Required Memory: 0.00 GB
Quantization is a technique used to reduce the precision of a model's parameters. Reducing the precision helps reduce the model's size by converting its weights from higher-precision data types (32-bit floats) to data types with a smaller footprint, such as 16-bit floats and integers. This has the effect of greatly reducing the model size and even increasing the inference speed by loading quicker and taking advantage of hardware accelerations. Because of these advantages, quantization has major implications for hobbyist hardware and even mobile devices.
Precision: 4
This little demonstration will hopefully aid in understanding quantization. You can think of each box as one bit of video memory. Each color section shows how much memory each quantitation takes.
In addition to parameters and quantization, there are also hardware and software-specific topics such as loaders. Loaders largely determine how the model is loaded into memory and what software systems can interact with it. In my experience, it is best to stick with the hardware and software ecosystem the developers for the model recommend. This avoids diving deeper into yet another complex topic.
When choosing a model you will come across many different ideas supported by a vast library of white papers that one could spend a lifetime reading and understanding. My recommendation is to try various models with your specific use case and determine what works best for your particular needs and tastes. For example, what works well for one programmer's workflow may not be suitable for another's workflow.
Interacting with models
Firstly, I want to say having started on Linux with an Nvidia GPU and later transiting to macOS, the easiest way to get started is with macOS using the LLMstudio, which makes all of this dead simple:
- Download a model.
- Load the model.
- Chat with the model.
There are a few settings that I would like to go further into detail with which will help you to take better advantage of these models:
Note
This is to be continued, I need to experiment with these settings to get some concert examples, and more info to finish writing about this.
Conclusion
LLMs are truly one of the most significant discoveries of humankind. It will be fascinating to watch how this field develops and what discoveries are in store for the future. I hope you have learned just a little about how these models work, how to select hardware, how to choose a model, and how to use the models. Thanks for reading and enjoying experimenting and learning something new.